网站首页被k后如何恢复权重 | 降权的原因分析和解决办法
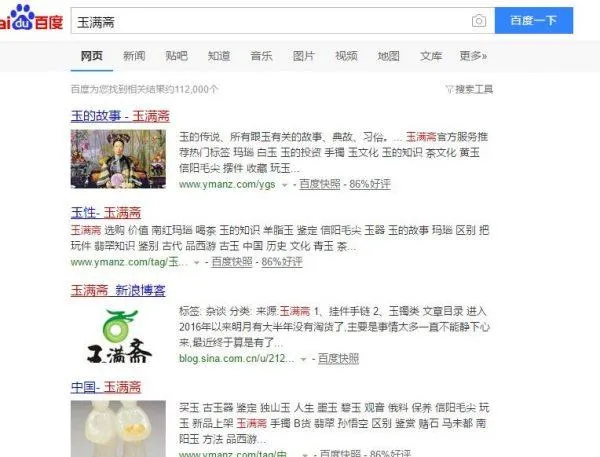
搜寻【玉满斋】的品牌词“玉满斋”浮现连首页都没有了,放心呀!
本来以为是百度算法调解的长久性问题,起头的时分1直没有重视,半个多月都过去了问题依然没有好转的迹象。这时候,我才感触应该是出问题了,于是顿时起头着抄本身排盘查题了,通过几天的阐发后创举首假设出现了1下几点问题:
1、歹意镜像众多紧急。
2、因疏忽删除了robots.txt,而主题已经不反对“www.主域名.com/page/”的链接模式,收录了1少量“www.主域名.com/page/”的无效链接,这些链接但凡指向“www.主域名.com”的。
3、主机因为配置欠妥形成顽固性下降,屡屡宕机,百度站长平台收录抓取报错屡次。
创举问题就顿时起头采取应对顺序:
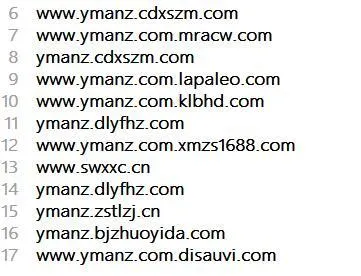
至今创举的歹意镜像和跳转的域名,好恶心呀!
歹意镜像的处置惩罚
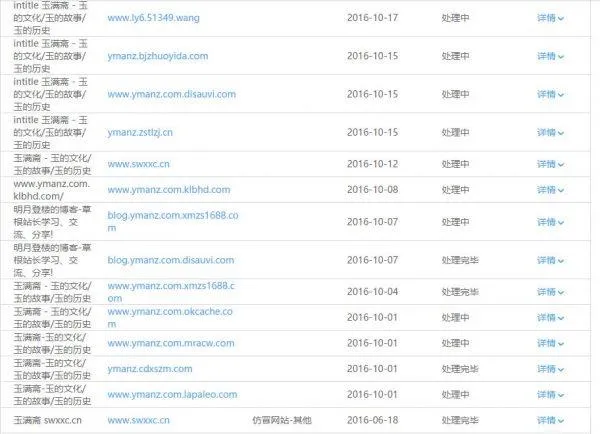
歹意镜像迩来众多成灾,创举很多博客都遇到这个问题,极端是在百度的搜寻结果里特其它多,google里这种问题确实没有,看来百度在这方面的技艺有待前进呀,至于这种歹意镜像实现原理据说是“反向 *** ”实现的,成本很是的低,预防顺序网上倒是良多,但通过我近1周的测试,有用的很少很少,收尾就找到1个踊跃跳转会指定域名代码有点成绩以及1个通过果断UA动静来防止歹意镜像的代码。通过近十天的行使感触也是治标不治本的设施,没有体例了只能采用最笨的设施,那即是向百度反馈和揭发了。
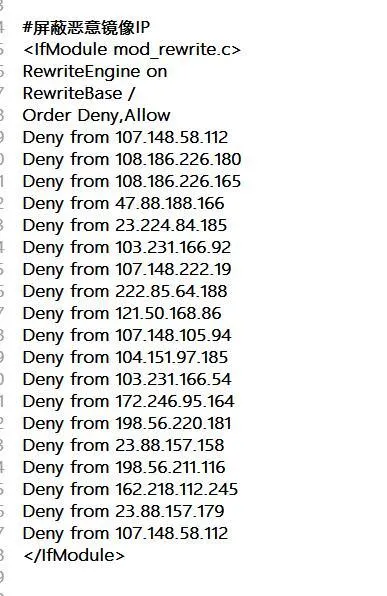
其它除了揭发和反馈外,还通过在百度里搜寻网站首页题目大约在结果里找到歹意镜像的网址域名并记实下去,通过ping剖析失掉IP,通过.htacess 来樊篱这个IP,这个义务要屡屡性的去做,积少成多的大约有用的中止歹意镜像的。
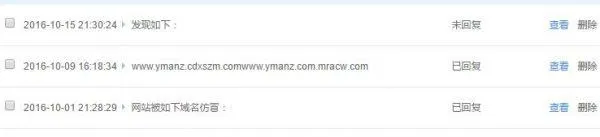
百度站长平台里的反馈
百度搜寻结果的“揭发”
用了1周光阴收罗图片截图证据后别离揭发和反馈,有些已经复兴并告之已处置惩罚,有些还在期待结果中,可是百度搜寻结果里的歹意镜像已经承减缓趋势了。
用到的代码下列(下列代码但凡增加到主题的Function.php里的,):
通过UA动静防止镜像
if(!is_admin()) { add_action("init", "deny_mirrored_request", 0);}function deny_mirrored_request(){ //获取UA动静$ua=$_SERVER["HTTP_USER_AGENT"];//将歹意USER_AGENT存入数组$now_ua=array("PHP","FeedDemon ","BOT/0.1 (BOT for JCE)","CrawlDaddy ","Java","Feedly","UniversalFeedParser","ApacheBench","Swiftbot","ZmEu","Indy Library","oBot","jaunty","YandexBot","AhrefsBot","MJ12bot","WinHttp","EasouSpider","HttpClient","Microsoft URL Control","YYSpider","jaunty","Python-urllib","lightDeckReports Bot");//制止空USER_AGENT,dedecms等主流收罗顺序但凡空USER_AGENT,部门sql注入工具也是空USER_AGENTif(!$ua) {header("Content-type: text/html; charset=utf-8");wp_die("严谨警告:请勿收罗本站,因为收罗的站长木有小JJ!");}else{ foreach($now_ua as $value )//果断能否是数组中存在的UA if(eregi($value,$ua)) { header("Content-type: text/html; charset=utf-8"); wp_die("严谨警告:请勿收罗本站,因为收罗的站长木有小JJ!"); }}}
非主域名的接见访问踊跃跳转至指定域名
(注:记得要将代码内的“主域名”批改为本身的域名哦)
add_action("wp_footer","deny_mirrored_网站sites");function deny_mirrored_网站sites(){ $currentDomain="www." + "主域名." + "com"; echo "";}
总结阐发:
今朝看来,揭发反馈仍是有成绩的,两个代码也起到了1些作用,究竟歹意镜像是为了借助镜像网站的流量来到达不行告人的目的的,直接跳转回指定域名对其反制仍是“有的放矢”的。
robots.txt的启用
因为疏忽删除了robots.txt,当初看来这是1个不行海涵的疏忽呀!在robots.txt加之“Disallow: /page/”制止搜寻引擎抓取,并且在百度站长平台里提交“www.主域名.com/page/”死链交往来往除搜寻结果里的这些无用链接,通过3-5天后搜寻结果里没有这些死链了。
总结阐发:
robots.txt文档仍是很是紧迫的,绝对是不能没有的,极端是国外网站,因为百度本身技艺的不行熟对于链接的阐发和辨析本事仍是托付家养的多1些,所以robots.txt1定要用好了,并且robots.txt的要随着网站的连接布局调解而中止响应的配置,这次首页品牌词权重的消散估计跟robots.txt有很大的干系,失效的“www.主域名.com/page/”应该是分化了首页链接的权重的。
主机的顽固性很关键
顽固主机根本上是个网站优化里陈词难听的话的问题了,可是对于1个喜爱折腾的草根站长来说,无意候真的是“No do!No die!”呀,不折腾就不会有那么多的问题,前1阵子为了好玩在侧边栏里参预了“百度打赏”的组件,没有想到形成了评论链接1直报“连接超时”的提示框,废了很大的光阴才找到是“百度打赏”的1段代码链接死链形成的。又因为折腾缓存插件缓存了全站的 *** 文档,形成网站评论提交后出现“404页面”都半个多月了才创举,囧呀!
总结阐发:
能不瞎折腾就不瞎折腾,要折腾也尽量在外地后行测试好了在折腾,有些怪异的妨碍但凡“折腾”形成的。
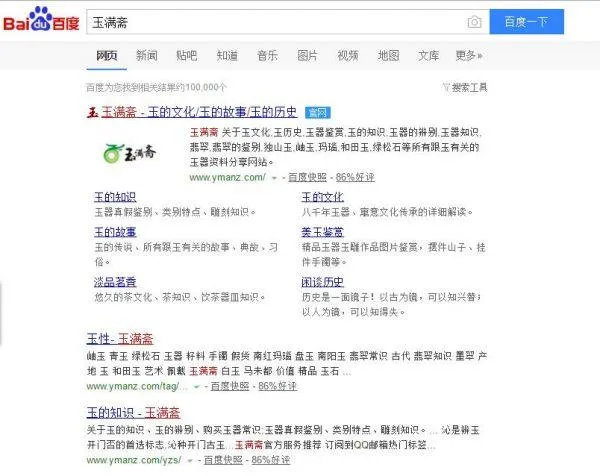
通过上述的这些调解后,究竟就在前天我的品牌词权重复原了,首页也归来了,扫数掉落的都归来了,唉!累死我了都!想想但凡本身作的呀!
博客相关内容
-

呼风唤雨的世纪第二课时教案
呼风唤雨的世纪第二课时教案,, 教学目标1、学会十二个生字,读准字音识记字形。2、了解科学技创造的奇迹及威力。3、感受科学技术发展的惊人速度及变化。4、能联生活实际,畅谈自己的感受及未来。教学时间2课时第一课一、谈话引入发散思维1、当你按动摇控器看电视的时候,学你打开冰箱取冷饮的时候,当你拨通电话和同学交谈的时候,当你登录网站查阅资料的时候……你是否感到科学技术的神奇威力。2、你还知道哪...
-

加权分数是什么意思
加权分数是什么意思,,加权分数是指不同的比重数据的分数叫做加权分数,加权分数是将原始的数据按照合理化的的比例来计算。如果要理解加权的意思,首先就需要理解什么是“权”,“权”在古时候的含义是秤砣,就是秤上面可以通过滑动来观察质量的铁疙瘩。《孟子-梁惠王上》里面说:“权,然后知轻重”。说的就是这个意思。在加权分数里面,除去一组数据里的其中一个数字的频数称其未权重外,权重还有其他更广泛的含义。统计学里认...
-

交管12123学法免分在哪
交管12123学法免分在哪,,学法免分只有在个别城市才有,如果自己所在的城市可以学法免分,在交管12123app的首页上就能看到,但是要实名注册。学法免分是通过做题,达到了一定分数之后可以免除一次扣分。在一个记分周期内,可以参与三次,这样就等于一个记分周期内可以免除9分。交管12123是一个非常好的app,通过这个app可以进行考试预约,违章处理,查询违章等。很多司机朋友不知道这个app,在处理违...
-

2009年流行歌曲排行榜,你最喜欢哪一首?
2009年流行歌曲排行榜,你最喜欢哪一首?,,2009十大网络热门新歌 1、小酒窝+江南Style《小酒窝》是筷子兄弟组合演唱的歌曲。这首歌是由王力宏作曲、方文山作词的。《江南style》,韩国著名歌手鸟叔PSY演唱的一首歌曲。由朴载相和TEDDY共同制作而成,《 江南 style 》在发布后便迅速风靡全球!该曲被作为韩剧(原来是美男啊)中的插曲而广受关注与喜爱,成为各大视频网站点击率最高的曲目之...
-
订车票软件哪个好用能退票(贴心!12306上新
订车票软件哪个好用能退票(贴心!12306上新多个便民功能),,进入12306网站,查询自己所购买车票的信息,点击退票按钮,最后确认退票。小新pro1612306网站登录12306网站首先登陆火车票订票官网,输入用户名和密码后,进入页面。进行退票购买车票后,在订单查在网上订后退票办法小新pro1612306网站登录12306网站首先登陆火车票订票官网,输入用户名和密码后,进入页面。进行退票购买车票...
-

december是哪一月?december是几月?
december是哪一月?december是几月?,,december是7月,从2010年5月开始,是一个有计划的品牌推广计划。从2010年4月到7月持续了近6个月。通过与不同品牌的合作,为不同品牌的产品宣传造势。比如为了让新产品在竞争激烈的市场上脱颖而出,同时为了推广自己的产品,吸引更多的人关注,提高自己产品的知名度。1、在中国大陆网站注册,上传产品图片或视频,以支持“december”网站的推...
-
微信看不到朋友圈是怎么回事
微信看不到朋友圈是怎么回事,,微信首页是最大的,也就是你最关注的地方。我很喜欢看你的朋友圈。每次看朋友圈都会想起当年和好姐妹一起在微信上晒幸福自拍的场景,那时候觉得很美好。微信里如果你看不到朋友圈,会是什么情况呢?微信上看不到朋友圈可能有两种原因:一种是手机自带的;另一种就是刷微信时,手机自动刷新内容,也就是我看到了朋友圈中有趣的人和事。可能大家对刷手机不陌生吧,手机自带的刷电视、刷手机玩游戏就会...
-
2009年流行歌曲排行榜,你最喜欢哪一首?
2009年流行歌曲排行榜,你最喜欢哪一首?,,2009十大网络热门新歌 1、小酒窝+江南Style《小酒窝》是筷子兄弟组合演唱的歌曲。这首歌是由王力宏作曲、方文山作词的。《江南style》,韩国著名歌手鸟叔PSY演唱的一首歌曲。由朴载相和TEDDY共同制作而成,《 江南 style 》在发布后便迅速风靡全球!该曲被作为韩剧(原来是美男啊)中的插曲而广受关注与喜爱,成为各大视频网站点击率最高的曲目之...
-
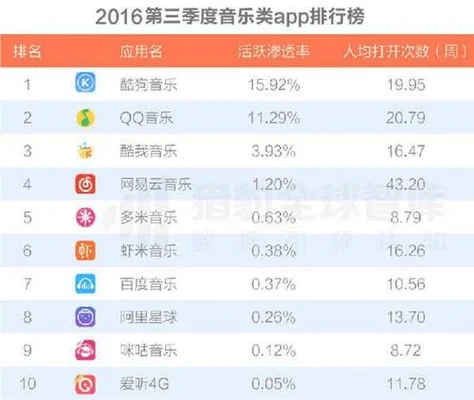
音乐播放软件排行榜前十名:你最喜欢哪一款
音乐播放软件排行榜前十名:你最喜欢哪一款?,,1、QQ音乐播放器2、百度音乐3、酷我4、酷狗5、虾米6、多米7、天天动听8、网易云9、千千静听10、腾讯听听1、qq音乐的优点:(1)资源多、更新快。(2)界面简洁大方;操作方便易用。(3)音质好,功能强大。(1)支持无损格式文件(MP3)、ape/wav等主流音轨;(2)提供歌词显示及下载;(3)在线试听;(4)智能匹配音效和歌曲类型(5)多种皮肤...
-
订车票软件哪个好用能退票(贴心!12306上新
订车票软件哪个好用能退票(贴心!12306上新多个便民功能),,进入12306网站,查询自己所购买车票的信息,点击退票按钮,最后确认退票。小新pro1612306网站登录12306网站首先登陆火车票订票官网,输入用户名和密码后,进入页面。进行退票购买车票后,在订单查在网上订后退票办法小新pro1612306网站登录12306网站首先登陆火车票订票官网,输入用户名和密码后,进入页面。进行退票购买车票...
-

december是哪一月?december是几月?
december是哪一月?december是几月?,,december是7月,从2010年5月开始,是一个有计划的品牌推广计划。从2010年4月到7月持续了近6个月。通过与不同品牌的合作,为不同品牌的产品宣传造势。比如为了让新产品在竞争激烈的市场上脱颖而出,同时为了推广自己的产品,吸引更多的人关注,提高自己产品的知名度。1、在中国大陆网站注册,上传产品图片或视频,以支持“december”网站的推...
-

合唱团最好听的十首歌:你听过哪几首?
合唱团最好听的十首歌:你听过哪几首?,,1、Bonnie and Clyde(邦尼和克莱德) 推荐理由:一首非常经典的爵士歌曲。这首歌是电影《毕业生》的主题曲之一,也是美国国家录音艺术与科学学会的世纪之声,被列入该协会20 世纪百大最佳唱片名单中。《毕业生》、《卡农》、《爱的纪念》、等经典名曲都是由它改编而成的。(来自百度音乐盒)2、Sing Something Big (唱支大的歌吧!)推荐意见...
-
微信看不到朋友圈是怎么回事
微信看不到朋友圈是怎么回事,,微信首页是最大的,也就是你最关注的地方。我很喜欢看你的朋友圈。每次看朋友圈都会想起当年和好姐妹一起在微信上晒幸福自拍的场景,那时候觉得很美好。微信里如果你看不到朋友圈,会是什么情况呢?微信上看不到朋友圈可能有两种原因:一种是手机自带的;另一种就是刷微信时,手机自动刷新内容,也就是我看到了朋友圈中有趣的人和事。可能大家对刷手机不陌生吧,手机自带的刷电视、刷手机玩游戏就会...
-

欧美流行音乐排行榜2022:第一首就是它,你
欧美流行音乐排行榜2022:第一首就是它,你猜到了吗?,,榜单名称: 2021年全球音乐收入榜发布日期:2021.12.29排名依据:1、《Billboard》杂志2月1日公布的数据3:《福布斯》网站4《时代周刊》《娱乐新闻报》5美国唱片业协会6尼尔森公司7SoundScan数据8英国国家统计局9Nielsen Soundscanner10Capital Cities LLC11HitFM12Ti...
-

破案悬疑电视剧:这到底怎么回事?难道是有人
破案悬疑电视剧:这到底怎么回事?难道是有人故意陷害吗?,,《法医秦明》 该剧讲述了法医师物鉴定人、刑警队大队长林涛与犯罪现场勘查人员周游龙携手在尸体解剖时历经的曲折离奇案件。 该剧于2018年3月23日在搜狐视频平台播出 ,并于同年5月在优酷视频网站同步上线 。2020年6月10日,《法医秦明2》开机仪式在北京举行。剧情简介 法医高亚男和警员陈诗羽(焦俊艳饰)因一场离奇的连环凶杀案而结识,两人从互...
-
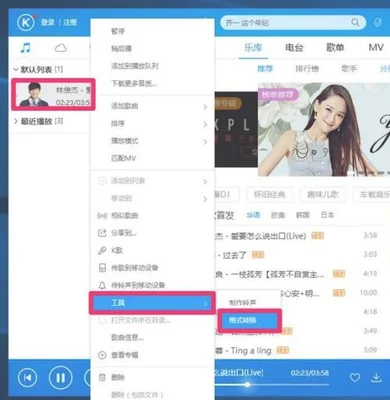
什么软件可以边听边转化文字(这里有你想
什么软件可以边听边转化文字(这里有你想知道的答案),,酷狗音乐软件怎样设置边听边存?下面和小编一起来了解一下吧!小米10 proMIUI13.0.4酷狗音乐11.3.0打开酷狗音乐软件,点击【酷狗音乐首页电量下方的三条横线】。点击【页面底部的设置】。点击【酷狗音乐软件怎样设置边听边存小米10 proMIUI13.0.4酷狗音乐11.3.0打开酷狗音乐软件,点击【酷狗音乐首页电量下方的三条横线】。点...
-

如何查看一本书的豆瓣评分?豆瓣读书如何查
如何查看一本书的豆瓣评分?豆瓣读书如何查书评?,,一、什么是豆瓣读书?1、 豆瓣网是阿北于2005年3月6日创建的网站。目前已经是中国国内领先的图书类网站之一;也是中国第一个倡导书评2.0,致力于帮助人们发现好书的网上社区和新型出版平台。2、 豆列:用户可以在豆瓣上记录自己的阅读感受与读书笔记,也可以发布书籍评论或对作者的评价等。3、 书单:提供多种类型的书目推荐服务,包括热门小说、经典名著、人文...
-

电脑入门培训教程免费视频,电脑小白必看!
电脑入门培训教程免费视频,电脑小白必看!,,1、首先我们打开百度首页搜索一下 电脑入门,然后点击第一个链接。2、在打开的页面中我们可以看到很多学习网站和软件下载工具等资源信息,选择自己感兴趣的学习资料进行查看即可(这里以360安全卫士为例子)。3、然后在浏览器中输入网址: 360安全中心 ,进入官网之后就可以找到很多的计算机知识、系统维护等方面的内容了!4、如果大家觉得以上这些课程还不够全面的话还...
